
Unsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyse and cluster unlabeled datasets. These algorithms discover hidden patterns or data groupings without the need for human intervention.
Its ability to discover similarities and differences in information makes it the ideal solution for exploratory data analysis, cross-selling strategies, customer segmentation, and image recognition. Join the Data Science Course in Chennai at FITA Academy and learn from the fundamentals
Common Methods in Unsupervised Learning
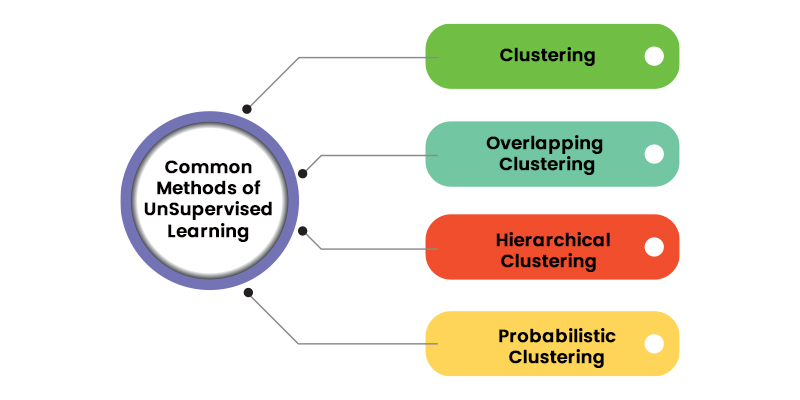
Unsupervised learning encompasses a range of techniques that serve three primary purposes: clustering, association, and dimensionality reduction. In the following sections, we will elucidate each learning approach and outline prevalent algorithms and strategies for their effective implementation.
Clustering
Clustering stands as a data mining method that organises unlabelled data based on their similarities or dissimilarities. Clustering algorithms are employed to transform unprocessed, unclassified data entities into sets characterised by inherent structures or patterns within the data. These clustering algorithms can be broadly classified into several types, including exclusive, overlapping, hierarchical, and probabilistic.
Exclusive and Overlapping Clustering
Exclusive clustering represents a grouping concept where a data point can belong to a single cluster exclusively, often referred to as “hard” clustering. An example of exclusive clustering is the K-means clustering algorithm.
K-means clustering serves as a prevalent illustration of an exclusive clustering technique, wherein data points are distributed into K clusters, with K signifying the number of clusters determined by the proximity to each cluster’s centroid. Data points that are closest to a particular centroid are grouped within the same category. A higher K value implies smaller, more finely-grained clusters, while a lower K value results in larger, coarser clusters. K-means clustering finds widespread application in market segmentation, document clustering, image segmentation, and image compression tasks.
Overlapping clustering diverges from exclusive clustering by permitting data points to be affiliated with multiple clusters, each with distinct degrees of membership. An instance of overlapping clustering is the “soft” or fuzzy k-means clustering.
Hierarchical Clustering
Hierarchical types of clustering also referred to as hierarchical cluster analysis (HCA), represents an unsupervised clustering algorithm that can be categorised into two primary modes: agglomerative and divisive. Agglomerative clustering is often described as a “bottom-up approach,” commencing with individual data points as distinct clusters and subsequently merging them iteratively based on their similarities until a single cluster is formed. Several methods are commonly employed to measure similarity, including:
- Ward’s linkage: This method defines the distance between two clusters based on the increase in the sum of squared distances after merging.
- Average linkage: This method computes the mean distance between data points within each cluster.
- Complete (or maximum) linkage: This method determines the maximum distance between data points in each cluster.
- Single (or minimum) linkage: This method identifies the minimum distance between data points in each cluster.
While Euclidean distance is the most frequently used metric for calculating these distances, other metrics, such as Manhattan distance, are also referenced in the types of clustering literature.
Divisive clustering, in contrast, represents the opposite of agglomerative clustering, adopting a “top-down” approach. In divisive clustering, a single data cluster is progressively divided based on dissimilarities between data points. Although divisive clustering is less commonly employed, it still holds significance within the realm of hierarchical clustering. These clustering procedures are typically visualised using a dendrogram—a tree-like diagram that records the merging or splitting of data points at each iteration.
Probabilistic Clustering
Probabilistic clustering is an unsupervised approach employed for addressing density estimation or soft clustering tasks. Within this framework, data points are grouped based on their likelihood of belonging to specific distributions. A widely utilised technique in probabilistic types of clustering is the Gaussian Mixture Model (GMM).
Gaussian Mixture Models fall into the category of mixture models, implying that they consist of an unspecified number of probability distribution functions. GMMs are primarily employed to ascertain the Gaussian or normal probability distribution to which a given data point is most likely associated. If the mean and variance were known, it would be straightforward to determine the distribution to which a data point belongs. However, in the case of GMMs, these parameters remain unknown. Hence, an assumption is made that a latent or concealed variable exists to effectively cluster the data points. While the use of the Expectation-Maximization (EM) algorithm is not mandatory, it is a frequently employed method for estimating the assignment probabilities of data points to specific data clusters.
Join the Data Science Course in Pune and learn more about being a data scientist and its opportunities
Applications of Unsupervised Learning
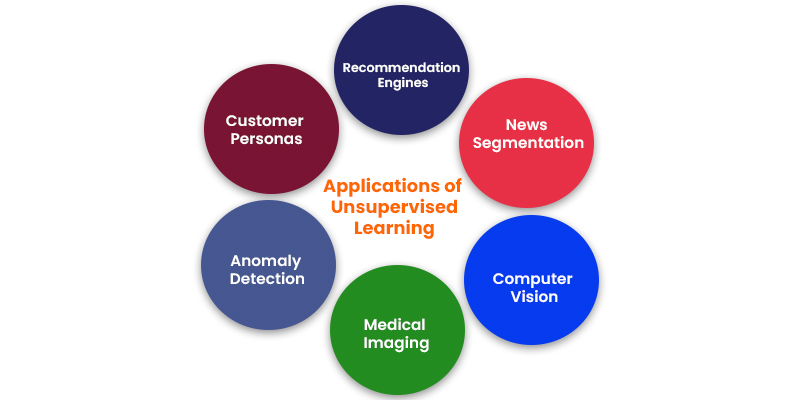
Machine learning techniques have become ubiquitous for enhancing user experiences and ensuring the quality of systems. Unsupervised learning, in particular, offers an exploratory approach to glean insights from data, facilitating the swift identification of patterns in vast datasets compared to manual analysis. Here are some prevalent real-world applications of unsupervised learning:
News Segmentation
Platforms like Google News employ unsupervised learning to categorise articles related to the same news story from diverse online sources. For instance, election results can be grouped under the “US” news category.
Computer Vision
Unsupervised learning algorithms play a pivotal role in visual perception tasks, including object recognition.
Medical Imaging
Unsupervised machine learning contributes essential capabilities to medical imaging devices used in radiology and pathology, enabling quick and accurate diagnosis through image detection, classification, and segmentation.
Anomaly Detection
Unsupervised learning models excel at sifting through extensive datasets to identify atypical data points, thereby detecting faulty equipment, human errors, or security breaches.
Customer Personas
Developing customer personas helps in understanding shared characteristics and purchasing behaviours among business clients. Unsupervised learning empowers organisations to construct more comprehensive buyer persona profiles, leading to better-aligned product messaging.
Recommendation Engines
Leveraging historical purchase data, unsupervised learning uncovers data trends that facilitate the development of more effective cross-selling strategies. This is particularly valuable for online retailers, as it enables the generation of relevant add-on recommendations for customers during the checkout process.
Start learning Machine Learning by joining Machine Learning Course in Chennai and advance yourself in the sector of artificial intelligence
Unsupervised vs. Supervised vs. Semi-Supervised Learning
Unsupervised learning, supervised learning, and semi-supervised learning are distinct approaches in the field of machine learning engineering, each with its own characteristics and applications.
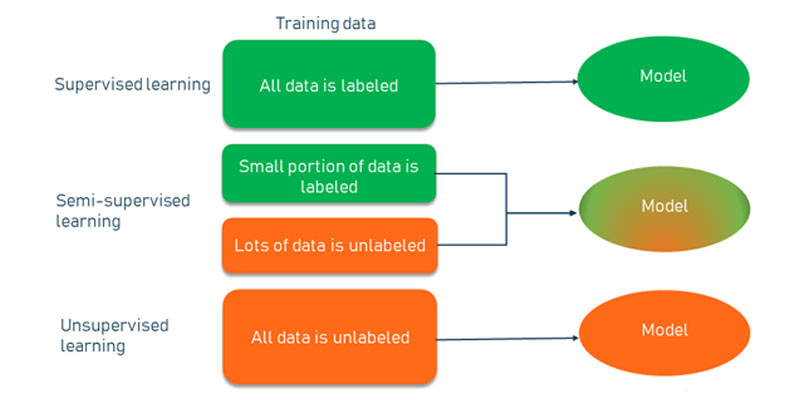
Unsupervised Learning
Data: Unsupervised learning algorithms work with unlabeled data, meaning there are no predefined categories or target outputs associated with the data.
Objective: The primary goal of unsupervised learning is to find hidden patterns, structures, or relationships within the data. It doesn’t make predictions or classifications based on predefined labels.
Examples: Clustering algorithms like K-means and hierarchical clustering, dimensionality reduction techniques like Principal Component Analysis (PCA), and generative models like Generative Adversarial Networks (GANs) are common examples.
Supervised Learning
Data: Supervised learning algorithms require labelled data, where each data point is associated with a known target or output value.
Objective: Supervised learning models use labelled data to learn patterns and relationships between input features and the corresponding target values. They make predictions or classify new, unseen data based on these learned patterns.
Examples: Linear regression, logistic regression, decision trees, support vector machines, and neural networks are typical supervised learning algorithms.
Semi-Supervised Learning
Data: Semi-supervised learning is an intermediate approach where only a portion of the data is labelled while the majority remains unlabeled.
Objective: Semi-supervised learning aims to leverage the limited labelled data along with the larger pool of unlabeled data to improve model performance. It combines elements of both supervised and unsupervised learning.
Applications: Semi-supervised learning can be advantageous in situations where labelling data is expensive or time-consuming. It allows models to benefit from some human-labeled data while taking advantage of the potential insights offered by unlabeled data.
unsupervised learning focuses on discovering underlying patterns in unlabeled data, supervised learning makes predictions or classifications based on labelled data, and semi-supervised learning bridges the gap by utilising a combination of labelled and unlabeled data to enhance model performance, particularly when obtaining labelled data is challenging or costly. Each approach has its strengths and uses cases, depending on the specific requirements of a machine learning task.
Challenges in Unsupervised Learning
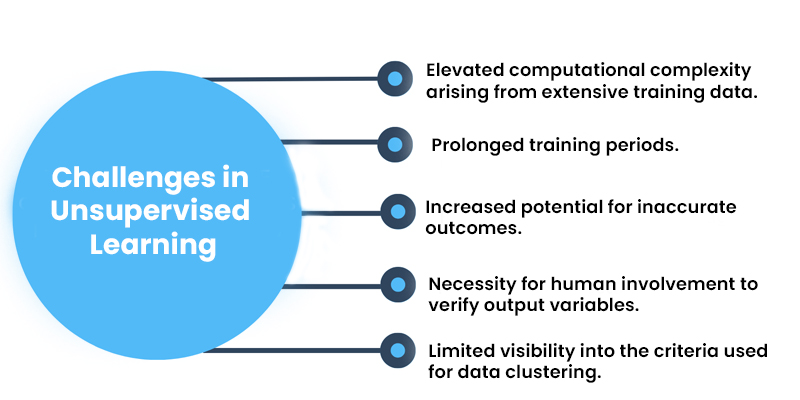
Although unsupervised learning offers numerous advantages, it can also present certain difficulties when machine learning algorithm models operate without human guidance. Some of these challenges encompass:
- Elevated computational complexity arising from extensive training data.
- Prolonged training periods.
- Increased potential for inaccurate outcomes.
- Necessity for human involvement to verify output variables.
- Limited visibility into the criteria used for data clustering.
Unsupervised learning stands as an integral and potent facet of data science, serving the pivotal role of extracting valuable insights and patterns from unstructured or unlabeled datasets. Leveraging diverse algorithms, including clustering and dimensionality reduction, unsupervised learning methods enable the discovery of latent structures, the grouping of akin data points, and the reduction of complexity within extensive datasets. While it may not yield explicit predictions or classifications akin to supervised learning, unsupervised learning assumes a pivotal role in data preprocessing, exploratory data analysis, and the revelation of concealed knowledge that, in turn, informs decision-making processes and fuels innovation across a multitude of industries. As the field of data science continues its evolution, the significance of unsupervised machine learning algorithms in uncovering latent insights within vast datasets remains paramount. Join Machine Learning Course in Bangalore at FITA Academy and start learning from the fundamentals of machine learning.
